How REBOL Works
Next section: Technical Elements
Prior section: About REBOL's Technology
The Web Model of Computing
The world wide web is based on the traditional client-server model. The data, functions, and much of the user interface resides on a server. The data is stored, searched, and manipulated by server functions that produce a static web page that is sent to a client device for display.
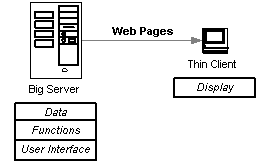
The client is, in essence, a dumb terminal that displays the user interface and handles user events, such as clicking a mouse. Whenever the user selects a button on the screen a message must be sent back to the server and the processing starts over again on the server to create the next page.
The REBOL Model of Computing
By contrast, REBOL's distributed computing model spreads the data, functions, and user interface components over the network. The data and code reside on both the server and the client. Data can be stored, searched, and manipulated by either the server or the client.
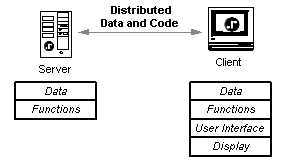
For instance, the user interface is created by functions that reside on the client, not on the server. The client displays information and interacts with the user. User events, such as selecting a button on the screen, are handled by the client for a much faster response. When necessary the client sends data back to a server or to another client.
More than Client-Server, Peer-to-Peer
The REBOL distributed computing model applies to more than just server-client interactions. All REBOL devices can make direct connections to other REBOL devices, allowing direct peer-to-peer communications to occur. Peer-to-peer connections help reduce network and server bottlenecks and provide a more private and direct channel for communications.
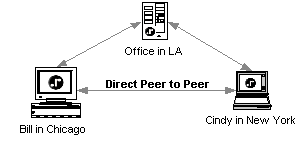
Establishing the peer-to-peer connection is done through a server that coordinates and manages the peer-to-peer activity. The server provides client rendezvous, enforces authentication, establishes security, and allows administrative control.