Chapitre 6 - Les Séries
Contenu
1. Historique de la traduction
2. Concepts de base
2.1 Parcourir une série
2.2 Sauts de valeurs
2.3 Extraire des valeurs
2.4 Extraire une sous-série
2.5 Insertion et Ajout
2.6 Enlever des valeurs
2.7 Modifier des valeurs
3. Fonctions relatives aux séries
3.1 Fonctions de création
3.2 Fonction de navigation
3.3 Fonctions d'Information
3.4 Fonctions d'extraction
3.5 Fonction de modification
3.6 Fonctions de recherche
3.7 Fonctions de tri
3.8 Fonctions de groupes de données
4. Types de données des séries
4.1 Types bloc
4.2 Types Chaîne de caractères
4.3 Pseudo-types
4.4 Fonction pour tester le type
5. Information sur les séries
5.1 Length?
5.2 Head?
5.3 Tail?
5.4 Empty?
5.5 Index?
5.6 Offset?
6. Créer et copier une série
6.1 Copie partielle
6.2 Copies de sous-séries
6.3 Copie afin d'initialiser
7. Iteration sur une série
7.1 Boucle Foreach
7.2 Boucle While
7.3 Boucle Forall
7.4 Boucle Forskip
7.5 La fonction Break
8. Recherche dans une série
8.1 Recherche simple
8.2 Résumé des raffinements
8.3 Recherche partielle
8.4 Position finale
8.5 Recherche en arrière
8.6 Recherches multiples
8.7 Correspondances
8.8 Recherche avec des caractères jokers (wildcards)
8.9 Fonction select
8.10 Recherche et remplacement
9. Trier une série
9.1 Tri simple
9.2 Tri par groupe
9.3 Fonctions de comparaison
10. Série en tant qu'ensemble de données
10.1 Unique
10.2 Intersect
10.3 Union
10.4 Difference
10.5 Exclude
11. Multiples variables de série
12. Raffinements de modification
12.1 Part
12.2 Only
12.3 Dup
1. Historique de la traduction
|
11 avril 2005 7:15
|
1.0.0
|
Traduction initiale
|
Philippe Le Goff
|
lp--legoff--free--fr
|
2. Concepts de base
Le concept de série est simple, et c'est un concept fondamental employé partout dans REBOL.
Afin de comprendre REBOL, vous devez comprendre comment créer et manipuler une série.
Une série est un ensemble de valeurs arrangées selon un ordre spécifique.
C'est aussi simple que cela.
1 2 3 4
A B C D
"ABCD"
10:30 4:20 7:11
Il existe différents types de séries en REBOL.
Un bloc, une chaîne de caractères, une liste,
une URL, un chemin (path), un email, un fichier, une balise, un binaire,
un jeu de caractères, un port, une table de hachage, une structure codée, et une image : voilà des
séries qui peuvent être manipulées avec le même ensemble commun de fonctions.
2.1 Parcourir une série
Une série est un ensemble ordonné de valeurs, vous pouvez la
parcourir d'une position à une autre.
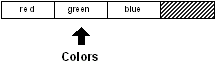
En guise d'exemple, prenons une série de trois couleurs
définie par le bloc suivant :
colors: [red green blue]
Il n'y a rien de particulier concernant ce bloc.
C'est une série contenant
trois mots. Elle constitue un ensemble de valeurs : red, green, et blue.
Les valeurs sont organisées selon cet ordre : red est en premier, green en second,
et blue en troisième.
La première position dans le bloc est appelée son début : head.
C'est la position qu'occupe
le mot : red. La dernière position dans le bloc est appelée sa fin : tail.
C'est une position située immédiatement après le dernier mot dans le bloc.
Si vous dessiniez un diagramme du bloc, il ressemblerait à ceci :
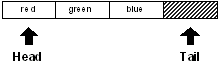
Remarquez que la fin (tail) est juste après la fin du bloc.
Ce point est important, il sera clarifié un peu plus loin.
La variable "colors" est utilisée pour faire référence au bloc. Elle est actuellement positionnée
sur le début head du bloc :
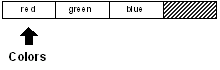
print head? colors
true
La variable "colors" est analogue à un curseur de position pour le bloc.
print index? colors
1
Le bloc a une longueur de : trois .
print length? colors
3
Le premier élément dans le bloc est :
print first colors
red
Le second élément dans le bloc est :
print second colors
green
Vous pouvez déplacer la variable "colors", notre curseur de position, le long du bloc en utilisant
différentes fonctions.
Pour déplacer la variable "colors" à la position suivante dans le bloc
de couleurs, utilisez la fonction : next
colors: next colors
La fonction next permet de se déplacer d'une valeur plus loin dans le bloc et retourne
la nouvelle position comme résultat. La variable "colors" est donc maintenant mise sur cette
nouvelle position :
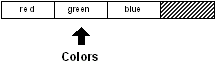
La position de la variable "colors" a donc été changée. Maintenant cette variable ne pointe plus
sur le début (head) du bloc :
print head? colors
false
Elle pointe sur la deuxième position dans le bloc :
print index? colors
2
D'autre part, si vous cherchez à obtenir le premier item de "colors", vous aurez :
print first colors
green
La position de la valeur retournée par la fonction first est relative à la position
courante de la variable "colors", le curseur, dans le bloc.
La valeur retournée n'est pas la première couleur
dans le bloc, mais la première couleur qui suit immédiatement la position courante du curseur "colors" dans
le bloc.
De la même manière, si vous recherchez la longueur du bloc ou la seconde couleur, celles-ci sont
aussi relatives à la position courante :
print length? Colors
2
print second colors
blue
Vous pouvez encore vous déplacer à la position suivante, et observer un fonctionnement similaire :
colors: next colors
print index? colors
3
print first colors
blue
print length? colors
1
Le schéma du bloc ressemble à présent à ceci :
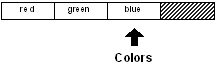
La variable "colors" est maintenant sur la dernière couleur dans le bloc,
mais elle n'est pas encore à la position finale (tail).
print tail? colors
false
Pour atteindre la fin, il faut encore se déplacer, avec next, à la position suivante :
colors: next colors
Maintenant, la variable "colors" pointe sur la fin du bloc (tail). Elle n'est plus
positionnée sur une couleur valide. La dernière couleur du bloc a été dépassée.
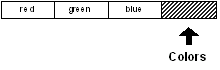
Si vous essayez le code suivant, vous obtiendrez :
print tail? colors
true
print index? colors
4
print length? Colors
0
print first colors
** Script Error: Out of range or past end.
** Where: print first colors
Vous recevez une erreur dans le dernier cas parce qu'il n'y a plus d'item
valide lorsque la fin du bloc a été dépassée.
Il est aussi possible de se déplacer en arrière dans le bloc. Si vous écrivez :
colors: back colors
vous vous déplacerez d'une position en arrière dans la série.
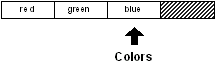
Tout le code suivant fonctionnera comme auparavant :
print index? colors
3
print first colors
blue
2.2 Sauts de valeurs
Les exemples précédents montraient comment se déplacer d'un élèment à la fois
dans la série.
Cependant, vous voudrez parfois parcourir la série en sautant plusieurs
items à la fois, avec la fonction skip.
Supposons que la variable "colors", notre curseur, soit placée au début de la série :
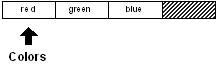
Vous pouvez aller en avant par saut de deux éléments avec le code suivant :
colors: skip colors 2
La fonction skip est similaire à la fonction next en ceci qu'elle retourne également la série
à la nouvelle position.
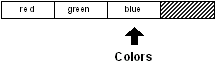
Pour contrôler l'index de la nouvelle position :
print index? colors
3
print first colors
blue
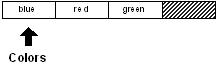
Pour un déplacement en arrière, utilisez skip avec une valeur négative :
colors: skip colors -1
Ce code ci-dessus a le même effet que la fonction back. En effet, un saut de -1 fait se déplacer
d'un élément en arrière.
print first colors
green
Notez que vous ne pouvez pas dépasser la fin ou le début d'une série.
Si vous essayez de faire cela, skip ira seulement aussi loin que possible. La fonction
ne génerera pas d'erreur. Si vous vous déplacez trop loin en avant, skip ira à la fin de la série :
colors: skip colors 20
print tail? colors
true
Si vous allez trop loin en arrière, skip renverra la série à son début :
colors: skip colors -100
print head? colors
true
Pour sauter directement au début de la série, utilisez plutôt la fonction head :
colors: head colors
print head? colors
true
print first colors
red
Vous pouvez retourner à la fin avec la fonction tail:
colors: tail colors
print tail? colors
true
2.3 Extraire des valeurs
Certains des exemples précédents faisaient usage des fonctions first et second
pour extraire d'une série des valeurs spécifiques. L'ensemble des fonctions ordinales est :
first
second
third
fourth
fifth
sixth
seventh
eighth
ninth
tenth
last
N.d.T.: les fonctions ordinales supérieures à fifth ont été rajoutées dans les dernières mises à jour de Core.
Ces fonctions ordinales sont fournies pour rendre plus pratique la récupération de valeurs
à partir de positions simples dans une série. Voici quelques exemples :
colors: [red green blue gold indigo teal]
print first colors
red
print third colors
blue
print fifth colors
indigo
print last colors
teal
Pour une extraction à partir d'une position numérique, utilisez la fonction pick :
print pick colors 3
blue
print pick colors 5
indigo
Une écriture simplifiée consiste à utiliser un "path" :
print colors/3
blue
print colors/5
indigo
Rappelez-vous, comme vu plus tôt, que la récupération d'une valeur est effectuée relativement
à la variable de série (le curseur) que vous fournissez.
Si la variable "colors" pointait une autre position dans la série, votre résultat aurait été différent.
L'extraction d'une valeur après la fin de la série retournerait une erreur avec les fonctions ordinales,
et none avec la fonction pick ou un "path" utilisant pick.
print pick colors 10
none
print colors/10
none
2.4 Extraire une sous-série
Vous pouvez extraire plusieurs valeurs d'une série avec la fonction copy.
Pour cela, utilisez copy avec le raffinement /part, en spécifiant le nombre de
valeurs à extraire :
colors: [red green blue]
sub-colors: copy/part colors 2
probe sub-colors
[red green]
Schématiquement, ceci devrait donner quelque chose comme :

Pour copier une sous-série depuis n'importe quelle position à l'intérieur de la série,
il faut d'abord se positionner sur une position de départ.
L'exemple suivant montre comment se déplacer à la seconde position dans la série,
avec la fonction next, avant d'effectuer la copie :
sub-colors: copy/part next colors 2
probe sub-colors
[green blue]
Ce qui devrait ressembler à :

la longueur de la liste à copier peut être indiquée comme position de fin, tout comme un nombre d'exemplaires.
Noter que la position indique où la copie devrait s'arrêter, pas la position de fin.
probe copy/part colors next colors
[red]
probe copy/part colors back tail colors
[red green]
probe copy/part next colors back tail colors
[green]
Ceci peut être utile avec la fonction find qui retourne comme résultat la position de la série :
file: %image.jpg
print copy/part file find file "."
image
2.5 Insertion et Ajout
Vous pouvez insérer une ou plusieurs nouvelles valeurs à n'importe quel endroit
dans la série en utilisant la fonction insert.
Quand on insére une valeur à une position dans la série, un espace est créé en décalant
les valeurs qui suivent vers la fin de la série.
Par exemple, le bloc :
colors: [red green]
devrait ressembler à :

Pour insérer une nouvelle valeur au début du bloc, là où le curseur (la variable "colors") est à présent positionné :
insert colors 'blue
Les mots 'red et 'green sont décalés et le mot 'blue est inséré au début de la liste (il a été préfixé par une apostrophe car il s'agit d'un mot,
à ne pas évaluer).
Notez que la variable "colors" demeure positionnée sur le début de la liste.
probe colors
[blue red green]
Notez encore que la valeur de retour de la fonction insert n'a pas été utilisée :
elle n'est pas passée à une variable ou à une fonction.
La ligne suivante permettrait d'affecter cette valeur retournée par insert à
la variable "colors" :
colors: insert colors 'blue
En ce cas, l'action sur le bloc serait identique à l'insertion de l'exemple précédent, mais
la position du curseur "colors" changerait. En effet, sa position devient ici la valeur retournée par insert.
La position renvoyée à partir d'insert est celle suivant immédiatement le point d'insertion.

Une insertion peut être faite n'importe où dans la série. La position de l'insertion peut être
spécifiée, et elle peut inclure la fin (tail).
Insérer une valeur en fin de série revient à faire un ajout à celle-ci.
colors: tail colors
insert colors 'gold
probe colors
[blue red green gold]
Avant l'insertion :

Après l'insertion :
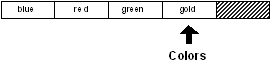
Le mot 'gold a été inséré en fin de série.
Un autre moyen d'insérer des valeurs à la fin d'une série est d'utiliser la fonction append.
Append fonctionne comme insert mais insére toujours les valeurs en
fin de liste. L'exemple précédent deviendrait :
append colors 'gold
Le résultat est identique.
Les fonctions insert et append accepte aussi un bloc d'argument à insérer.
Par exemple,
colors: [red green]
insert colors [blue yellow orange]
probe colors
[blue yellow orange red green]
Si vous voulez insérer de nouvelles valeurs entre les mots red et green :
colors: [red green]
insert next colors [blue yellow orange]
probe colors
[red blue yellow orange green]
Les fonctions insert et append possédent d'autres possibilités, avec leurs raffinements,
qui seront détaillées ultérieurement dans un autre section.
2.6 Enlever des valeurs
Vous pouvez ôter une ou plusieurs valeurs depuis n'importe quel endroit de la série
en utilisant la fonction remove.
Par exemple, avec le bloc :
colors: [red green blue gold]
comme schématisé ici :
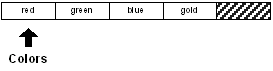
vous pouvez enlever le premier élément du bloc avec la ligne :
remove colors
Le bloc devient :
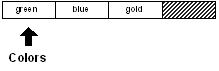
Son contenu peut être édité avec :
probe colors
[green blue gold]
La fonction remove ôte des valeurs relativement à la position courante
de notre curseur, la variable "colors".
Vous pouvez enlever des valeurs depuis n'importe quel endroit dans la série en indiquant la position.
remove next colors
Le bloc ressemble à présent à :

Plusieurs éléments peuvent être ôtés en utilisant le raffinement /part.
remove/part colors 2
Ceci enlève les valeurs restantes, laissant un bloc vide :

Comme pour insert/part, l'argument fourni à remove/part peut aussi être une position à
l'intérieur du bloc.
Effacer toutes les valeurs restantes est une opération courante.
La fonction clear permet de faire cela directement.
Clear enlève toutes les valeurs depuis la position courante jusqu'à la fin.
Par exemple :
Colors: [blue red green gold]
comme montré ici :

Tout ce qui se trouve après le mot blue peut être ôté avec :
clear next colors
Le bloc devient :
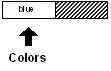
Vous pouvez entièrement vider le bloc avec :
clear colors
2.7 Modifier des valeurs
Un jeu suplémentaire de fonctions est fourni pour
permettre la modification de valeurs dans une série.
La fonction change remplace une ou plusieurs valeurs par des nouvelles.
Quoique ceci puisse être fait avec les fonctions insert et append, il est plus efficace
d'utiliser change.
Le bloc suivant est défini :
colors: [blue red green gold]

Sa deuxième valeur peut être changée avec la ligne :
change next colors 'yellow
et le bloc devient :

Le bloc est devenu à présent :
probe colors
[blue yellow green gold]
La fonction poke vous permet d'effectuer un changement à une position particulière,
relativement au curseur, la variable "colors".
La fonction poke est similaire à la fonction pick décrite précédemment.
poke colors 3 'red
Le bloc est à présent :

avec :
probe colors
[blue yellow red gold]
La fonction change possède des raffinements qui seront décrits plus loin.
3. Fonctions relatives aux séries
Voici un résumé des fonctions relatives aux séries.
La plupart d'entre elles ont déjà été décrites en détail dans les sections précédentes. D'autres
seront explicitées plus loin.
3.1 Fonctions de création
|
make
|
Crée une nouvelle série d'un certain type.
| |
copy
|
Copie une série
|
3.2 Fonction de navigation
|
next
|
Retourne la position suivante dans la série.
| |
back
|
Retourne la position précédente dans la série.
| |
head
|
Retourne la position du début dans la série.
| |
tail
|
Retourne la position de fin dans la série.
| |
skip
|
Retourne la position plus ou moins un entier.
| |
at
|
Retourne la position plus ou moins un entier, mais en utilisant la même indexation
que la fonction pick.
|
3.3 Fonctions d'Information
|
head?
|
Retourne true si le curseur est sur le début de la série.
| |
tail?
|
Retourne true si le curseur est sur la fin de la série.
| |
index?
|
retourne l'index par-rapport au début de la série.
| |
length?
|
retourne la longueur d'une série à partir de la position courante.
| |
offset?
|
retourne la distance entre deux positions dans la série.
| |
empty?
|
retourne true si la série est vide à partir de cette position.
|
3.4 Fonctions d'extraction
|
pick
|
extrait une valeur unique à partir d'une position dans une série.
| |
copy/part
|
extrait une sous-série à partir d'une série.
| |
first
|
extrait la première valeur d'une série.
| |
second
|
extrait la seconde valeur d'une série.
| |
third
|
extrait la troisième valeur d'une série.
| |
fourth
|
extrait la quatrième valeur d'une série.
| |
fifth
|
extrait la cinquième valeur d'une série.
| |
sixth
|
extrait la sixième valeur d'une série.
| |
seventh
|
extrait la septième valeur d'une série.
| |
eigth
|
extrait la huitième valeur d'une série.
| |
ninth
|
extrait la neuvième valeur d'une série.
| |
tenth
|
extrait la dixième valeur d'une série.
| |
last
|
extrait la dernière valeur d'une série.
|
3.5 Fonction de modification
|
insert
|
insére des valeurs dans une série.
| |
append
|
ajoute des valeurs à la fin d'une série.
| |
remove
|
ôte des valeurs d'une série.
| |
clear
|
efface les valeurs de la position courante jusqu'à la fin de la série.
| |
change
|
modifie les valeurs dans une série.
| |
poke
|
modifie les valeurs à une position donnée, dans une série.
|
3.6 Fonctions de recherche
|
find
|
recherche une valeur dans une série.
| |
select
|
recherche une valeur dans une série et en cas de succés renvoie les valeurs qui suivent
| |
replace
|
cherche et remplace des valeurs dans une série.
| |
parse
|
parse les valeurs dans une série.
|
3.7 Fonctions de tri
|
sort
|
trie les valeurs d'une série dans un ordre.
| |
reverse
|
inverse l'ordre des valeurs dans une série
|
3.8 Fonctions de groupes de données
|
unique
|
retourne un ensemble de données uniques, en ayant supprimé les doublons.
| |
intersect
|
renvoie seulement les valeurs trouvées communes aux deux séries.
| |
union
|
retourne l'union de deux séries.
| |
difference
|
renvoie les valeurs non communes à chaque série.
| |
exclude
|
retourne toutes les valeurs de la première série en argument,
moins celles, communes aux deux, de la deuxième série
|
4. Types de données des séries
Tous les types de données des séries peuvent être regroupés en deux grandes catégories.
Chaque catégorie comprend la valeur du type de données (datatype) et la fonction testant ce type.
4.1 Types bloc
|
Block!
|
blocs de valeurs
| |
Paren!
|
blocs de valeurs entre parenthèses
| |
Path!
|
paths de valeurs
| |
List!
|
listes
| |
Hash!
|
tableaux associatifs
|
4.2 Types Chaîne de caractères
|
String!
|
chaînes de caractères
| |
Binary!
|
suite d'octets
| |
Tag!
|
balises HTML et XML
| |
File!
|
noms de fichiers
| |
URL!
|
urls
| |
Email!
|
emails
| |
Image!
|
données d'Image
| |
Issue!
|
codes particuliers
|
4.3 Pseudo-types
Les types de données de séries sont regroupés aussi en quelques pseudo-types
qui rendent plus facile le test d'un type et la gestion des arguments de fonctions :
|
series!
|
un type de donnée "series"
| |
any-block!
|
n'importe que type de donnés "bloc"
| |
any-string!
|
n'importe quel type de données "chaîne"
|
4.4 Fonction pour tester le type
Tests du type Bloc :
block? paren? path? list? hash?
Tests du type chaîne :
string? binary? tag? file? url? email? image? issue?
Autres fonctions de tests de pseudo-type :
series? any-block? any-string?
5. Information sur les séries
5.1 Length?
La longueur d'une série est le nombre d'items (éléments pour
un bloc, ou caractères pour une chaîne) depuis la position courante jusqu'à la fin de
la série.
La fonction length? renvoie le nombre d'items jusqu'à la fin.
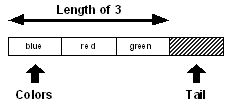
colors: [blue red green]
print length? colors
3
Les trois éléments sont comptabilisés pour le calcul de la longueur :
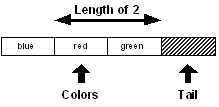
Si la variable "colors" est avancée à la position suivante,
colors: next colors
print length? colors
2
la longueur devient : deux .
Autres exemples d'usage de length? :
print length? "Ukiah"
5
print length? []
0
print length? ""
0
data: [1 2 3 4 5 6 7 8]
print length? data
8
data: next data
print length? data
7
data: skip data 5
print length? data
2
5.2 Head?
Le début de la série est la position de sa première valeur.
Si une série est à son début, la fonction head? renvoie true :
data: [1 2 3 4 5]
print head? data
true
data: next data
print head? data
false
5.3 Tail?
La fin de la série est la position qui suit immédiatement la dernière valeur valide.
Si la variable de série pointe sur la fin, la fonction tail? renverra true :
data: [1 2 3 4 5]
print tail? data
false
data: tail data
print tail? data
true
5.4 Empty?
La fonction empty? est équivalente à la fonction tail?.
print empty? data
true
Si la fonction empty? renvoie true, cela signifie qu'il n'y a plus de valeurs entre la
position courante et la fin de la série.
Cependant, il peut rester des valeurs dans la série.
Ces valeurs peuvent être présentes avant la position courante.
Si vous voulez déterminer si la série est vide du début à la fin, utilisez :
print empty? head data
false
5.5 Index?
L'index est la position dans la série relativement à son début. Afin de connaître cette information
pour une variable de série, il faut utiliser la fonction index? :
data: [1 2 3 4 5]
print index? data
1
data: next data
print index? data
2
data: tail data
print index? data
6
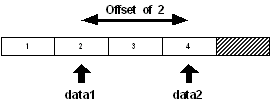
5.6 Offset?
L'écart entre deux positions au sein d'une série peut être déterminé avec la fonction offset?.
data: [1 2 3 4]
data1: next data
data2: back tail data
print offset? data1 data2
4
Dans cet exemple, l'écart est la différence entre la position 2 et la position 4 :
6. Créer et copier une série
Une nouvelle série peut être créée avec les fonctions make et copy.
La fonction make peut servir à créer une nouvelle série à partir
d'un type de données et d'une taille initiale.
La taille est une estimation de ce qui serait nécessaire pour la série.
Si la taille initiale est trop petite, celle-ci sera automatiquement augmentée,
mais avec une petite perte de performances.
block: make block! 50
string: make string! 10000
list: make list! 128
file: make file! 64
La fonction copy crée une nouvelle série en dupliquant une série existante :
string: copy "Message in a bottle"
new-string: copy string
block: copy [1 2 3 4 5]
new-block: copy block
La fonction copy est également importante, en pratique, avec les fonctions qui modifient le contenu d'une série.
Par exemple, si vous voulez changer la casse d'une chaîne de caractères sans modifier l'original, employez copy :
string: uppercase copy "Message in a bottle"
6.1 Copie partielle
La fonction copy utilise le raffinement /part qui prend un seul et unique argument,
pouvant être soit un nombre entier (le nombre à copier d'éléments de la série ),
soit une position dans la série indiquant la dernière position pour la copie.
str: "Message in a bottle"
print str
Message in a bottle
print copy/part str find str " "
Message
new-str: copy/part (find str "in") (find str "bottle")
print new-str
in a
blk: [ages [10 12 32] sizes [100 20 30]]
new-blk: copy/part blk 2
probe new-blk
[ages [10 12 32]]
6.2 Copies de sous-séries
Des blocs peuvent contenir d'autres blocs, et/ou des chaînes.
Quand un tel bloc est copié, ses sous-series ne le sont pas.
Les sous-séries sont référencées directement et ont les mêmes données de série que le bloc original.
Si vous modifiez l'une ou l'autre de ces sous-séries, vous les modifiez également dans le bloc d'origine.
Le raffinement copy/deep forcera la copie de toutes les sous-séries à l'intérieur d'un bloc :
blk-one: ["abc" [1 2 3]]
probe blk-one
["abc" [1 2 3]]
L'exemple suivant effectue une copie normale de "blk-one" vers "blk-two" :
blk-two: copy blk-one
probe blk-one
["abc" [1 2 3]]
probe blk-two
["abc" [1 2 3]]
Si la chaîne (ou le bloc) contenue dans "blk-two" est modifiée, les valeurs contenues dans la série blk-one
sont elles aussi modifiées.
append blk-two/1 "DEF"
append blk-two/2 [4 5 6]
probe blk-one
["abcDEF" [1 2 3 4 5 6]]
probe blk-two
["abcDEF" [1 2 3 4 5 6]]
Utiliser copy/deep permet la copie de toutes les valeurs de type "série" trouvées dans le bloc :
blk-two: copy/deep blk-one
append blk-two/1 "ghi"
append blk-two/2 [7 8 9]
probe blk-one
["abcDEF" [1 2 3 4 5 6]]
probe blk-two
["abcDEFghi" [1 2 3 4 5 6 7 8 9]]
6.3 Copie afin d'initialiser
L'utilisation de copy sur une série de type chaîne ou bloc permet de créer une série unique :
str: copy ""
blk: copy []
En utilisant copy, on s'assure qu'une nouvelle série sera initialisée pour un mot
chaque fois que ce mot sera initialisé.
Voici un exemple qui illustre l'importance de cela :
print-it: func [/local str] [
str: ""
insert str "ha"
print str
]
print-it
ha
print-it
haha
print-it
hahaha
Dans cet exemple, parce que copy n'a pas été utilisé, la série vide "str", de type chaîne,
est modifiée à chaque appel de la fonction "print-it".
La chaîne "ha" est insérée dans la série "str" chaque fois que "print-it" est appelée.
L'examen du code source de print-it montre le noeud du problème :
source print-it
print-it: func [/local str] [
str: "hahaha" <-- ici
insert str "ha"
print str
]
Bien que "str" soit une variable locale, sa valeur est globale.
Pour éviter ce problème, la fonction devrait copier une chaîne vide ou utiliser make string!.
print-it: func [/local str] [
str: copy ""
insert str "ha"
print str
]
print-it
ha
print-it
ha
print-it
ha
7. Iteration sur une série
Une boucle est nécessaire pour parcourir la série. Il existe quelques fonctions pour cela
qui peuvent aider à automatiser ce processus d'itération.
7.1 Boucle Foreach
La fonction foreach permet de parcourir une série en ayant définit un mot ou plusieurs mots
décrivant les valeurs dans la série.
La fonction foreach prend trois arguments : un mot ou un bloc de mots qui manipule les valeurs
pour chaque itération, la série, et finalement un bloc à évaluer lors de chaque itération.
colors: [red green blue yellow orange gold]
foreach color colors [print color]
red
green
blue
yellow
orange
gold
foreach [c1 c2] colors [print [c1 c2]]
red green
blue yellow
orange gold
foreach [c1 c2 c3] colors [print [c1 c2 c3]]
red green blue
yellow orange gold
Ceci est très pratique avec des blocs contenant des données reliées entre elles :
people: [
"Bob" bob@example.com 12
"Tom" tom@example.net 40
"Sam" sam@example.org 22
]
foreach [name email age] people [
print [name email age]
]
Bob bob@example.com 12
Tom tom@example.net 40
Sam sam@example.org 22
Remarquez que la fonction foreach n'avance pas l'index courant
dans la série, de sorte qu'il n'est pas nécessaire de remettre à zéro la variable représentant la série.
7.2 Boucle While
L'approche la plus flexible est d'utiliser une boucle while,
qui vous permet de faire sans problèmes ce que vous voulez avec la série :
colors: [red green blue yellow orange]
while [not tail? colors] [
print first colors
colors: next colors
]
red
green
blue
yellow
orange
La méthode ci-dessous montre comment insérer des valeurs sans saisir de doublons :
colors: head colors
while [not tail? colors] [
if colors/1 = 'yellow [
colors: insert colors 'blue
]
colors: next colors
]
L'exemple illustre aussi comment insert renvoie la position immédiatement suivant l'insertion.
Pour effacer une valeur sans en sauter accidentellement une , utilisez le code suivant :
colors: head colors
while [not tail? colors] [
either colors/1 = 'blue [
remove colors
][
colors: next colors
]
]
Remarquez que si remove a été utilisée, la fonction next n'est pas appelée.
7.3 Boucle Forall
La fonction forall est identique à while, mais simplifie encore l'approche.
La boucle avec forall démarre à partir de l'index courant et parcourt la série jusqu'à la fin
en évaluant un bloc à chaque itération.
La fonction forall prend deux arguments : une variable de série et le bloc à évaluer à chaque itération.
colors: [red green blue yellow orange]
forall colors [print first colors]
red
green
blue
yellow
orange
Forall parcourt la série en avancant le curseur à chaque itération, de sorte que
la variable de série "colors" sera positionnée sur la fin de la série, lorsque la boucle sera terminée :
print tail? colors
true
Par conséquent, cette variable de série "colors" doit être remise à zéro avant d'être à nouveau employée :
colors: head colors
Egalement, si un bloc évalué modifie la série, attention à éviter les trous ou les répétitions de valeurs.
La fonction forall fonctionne bien dans la plupart des cas; mais si vous avez un doute, utilisez while à la place.
forall colors [
if colors/1 = 'blue [remove colors]
print first colors
]
red
green
yellow
orange
7.4 Boucle Forskip
Tout comme forall, la fonction forskip parcourt la série en partant de la position courante,
mais saute un nombre spécifié de valeurs à chaque fois.
La fonction forskip prend trois arguments : une variable de série, le nombre de valeurs à sauter
entre deux itérations, et le bloc à évaluer à chaque itération.
colors: [red green blue yellow orange]
forskip colors 2 [print first colors]
red
blue
orange
La fonction forskip laisse la série à sa fin, nécessitant de la remettre au début si besoin.
print tail? colors
true
colors: head colors
7.5 La fonction Break
N'importe laquelle de ces boucles peut être arrêtée à tout moment avec la fonction break
placée dans le bloc d'évaluation.
Voyez le chapitre du Manuel Utilisateur concernant les Expressions
pour plus d'informations sur la fonction break.
8. Recherche dans une série
La fonction find recherche au travers d'une série de type bloc ou chaîne une valeur ou un modèle.
Cette fonction possède de nombreux raffinements qui permettent beaucoup de variations dans les paramètres de recherche.
8.1 Recherche simple
L'usage le pus courant et le plus simple pour la fonction find est de rechercher
une valeur dans un bloc ou une chaîne. Dans ce cas, find nécessite seulement deux arguments :
la série où chercher et la valeur à trouver.
Un exemple d'utilisation de find sur un bloc :
colors: [red green blue yellow orange]
where: find colors 'blue
probe where
[blue yellow orange]
print first where
blue
La fonction find peut aussi rechercher des valeurs selon le type de données.
Ceci peut être très utile :
items: [10:30 20-Feb-2000 Cindy "United"]
where: find items date!
print first where
20-Feb-2000
where: find items string!
print first where
United
Un exemple d'utilisation de find sur une chaîne est :
colors: "red green blue yellow orange"
where: find colors "blue"
print where
blue yellow orange
Lorsqu'une recherche échoue, la valeur none est renvoyée.
colors: [red green blue yellow orange]
probe find colors 'indigo
none
8.2 Résumé des raffinements
Find possède plusieurs raffinements qui autorisent une grande variété de
paramétres de recherche :
|
/part
|
limite la recherche dans une série à une longueur donnée ou une position de fin.
| |
/only
|
Manipule une valeur de série comme une valeur unique
| |
/case
|
Utilise une comparaison de chaînes sensible à la casse (maj/min).
| |
/any
|
Permet d'utiliser des caractères jokers ("wildcards") autorisant des correspondances avec n'importe quel(s) caractère(s) :
un astérisque (*) dans le modéle signifie : n'importe quelle chaîne, et un point d'interrogation (?)
correspond à : n'importe quel caractère.
| |
/with
|
Permet l'usage de caractères jokers ("wildcards") avec des caractères différents de l'astérisque (*) et du
point d'interrogation (?). Ceci permet d'avoir un modéle contenant des astérisques et des points d'interrogation.
| |
/match
|
Recherche un modéle commencant à la position courante de la série,
plutôt que de chercher la première occurence d'une valeur ou d'une chaîne.
Renvoie la position de fin de la correspondance si celle-ci est trouvée.
| |
/tail
|
renvoie la position qui suit la correspondance sur une recherche fructueuse,
plutôt que de renvoyer la position de la correspondance.
| |
/last
|
Recherche en arrière d'une correspondance, en commencant à la fin de la série.
| |
/reverse
|
Recherche en arrière d'une correspondance, en commencant à la position courante.
|
8.3 Recherche partielle
Le raffinement /part permet que la recherche soit limitée à une portion spécifique de la série.
par exemple, vous pouvez vouloir restreindre une recherche à une ligne donnée
ou à une portion de texte.
Tout comme insert/part et remove/part,
find/part prend en argument soit un nombre, soit une position de fin .
L'exemple suivant restreint la recherche aux trois premiers items :
colors: [red green blue yellow blue orange gold]
probe find/part colors 'blue
[blue yellow blue orange gold]
La recherche suivante sur une chaîne est restreinte aux 15 premiers caractères:
text: "Keep things as simple as you can."
print find/part text "as" 15
as simple as you can.
L'exemple ci-dessous utilise un marquage de positions.
La recherche est réduite à une seule ligne de texte :
text: {
This is line one.
This is line two.
}
start: find text "this"
end: find start newline
item: find/part start "line" end
print item
line one.
8.4 Position finale
La fonction find retourne la position dans la série où un item a été trouvé.
Le raffinement /tail renverra la position qui suit immédiatement l'item trouvé.
Voici un exemple :
filename: %script.txt
print find filename "."
.txt
print find/tail filename "."
txt
clear change find/tail filename "." "r"
print filename
script.r
Dans cet exemple, clear est nécessaire pour enlever "xt" qui suit "t".
8.5 Recherche en arrière
Le dernier exemple de la section précédente ne marcherait pas si le
nom du fichier possédait plus d'un point "."
Par exemple :
filename: %new.script.txt
print find filename "."
.script.txt
Dans cet exemple, nous voulons la dernière occurence (la dernière correspondance trouvée)
du point "." dans la chaîne.
Celle-ci peut être trouvée en utilisant le raffinement /last.
Le raffinement /last permet une rechercher arrière au travers d'une série.
print find/last filename "."
.txt
Le raffinement /last peut être combiné avec /tail pour produire :
print find/last/tail filename "."
txt
Si vous voulez continuer à rechercher en arrière dans la chaîne, vous aurez besoin du raffinement /reverse.
Ce raffinement permet une recherche arrière à partir de la position courante jusqu'au début de la série,
plutôt qu'une recherche depuis le début jusqu'à la fin.
where: find/last filename "."
print where
.txt
print find/reverse where "."
.script.txt
Notez que /reverse continue la recherche juste après la position de la dernière correspondance.
Ceci évite de retrouver deux fois le même point "." encore .
8.6 Recherches multiples
Vous pouvez facilement réutiliser la fonction find pour chercher des occurrences multiples d'une valeur
ou d'une chaîne.
Voici un exemple qui devrait afficher toutes les chaînes rencontrées dans un bloc :
blk: load %script.r
while [blk: find blk string!] [
print first blk
blk: next blk
]
L'exemple suivant compte le nombre de nouvelles lignes dans un script.
Il utilise juste le raffinement /tail pour éviter une boucle infinie et
renvoie donc la position qui est immédiatement après la correspondance.
text: read %script.r
count: 0
while [text: find/tail text newline] [count: count + 1]
Pour effectuer une recherche répétée en arrière, utiliser le raffinement /reverse.
L'exemple suivant affiche toutes les index de positions dans l'ordre inverse pour le texte d'un script :
while [text: find/reverse tail text newline] [
print index? text
]
8.7 Correspondances
Le raffinement /match modifie le comportement de find pour effectuer une rechercher de modéle
à la position courante de la série.
Ce raffinement permet aux opérations de parsing d'être effectuées en recherchant dans la suite de la série des correspondances
avec le modéle fourni.
Voir le chapitre concernant le Parsing pour la recherche d'items.
Un simple exemple de recherche de correspondance est le suivant :
blk: [1432 "Franklin Pike Circle"]
probe find/match blk integer!
["Franklin Pike Circle"]
probe find/match blk 1432
["Franklin Pike Circle"]
probe find/match blk "test"
none
str: "Keep things simple."
probe find/match str "keep"
" things simple."
print find/match str "things"
none
Remarquez dans cet exemple qu'aucune recherche n'est réalisée.
Soit le commencement de la série correspond, soit il ne correspond pas.
Si il y a une correspondance, la variable de série est alors avancée à la position qui
suit immédiatement l'item trouvé, permettant l'analyse de la séquence suivante.
Voici un exemple d'analyseur écrit avec find/match :
grammar: [
["keep" "make" "trust"]
["things" "life" "ideas"]
["simple" "smart" "happy"]
]
parse-it: func [str /local new] [
foreach words grammar [
foreach word words [
if new: find/match str word [break]
]
if none? new [return false]
str: next new ;skip space
]
true
]
print parse-it "Keep things simple"
true
print parse-it "Make things smart"
true
print parse-it "Trust life well"
false
La recherche de modéle peut être rendue sensible à la casse avec le raffinement /case ( distinction majuscules/minuscules).
Les possibilités de /match peuvent être grandement étendues avec l'usage du raffinement /any.
8.8 Recherche avec des caractères jokers (wildcards)
Le raffinement /any permet d'utiliser des caractères jokers (wildcards) pour une recherche.
Le point d'interrogation (?) et l'astérisque (*) agissent comme des caractères de substitution
pour remplacer respectivement "un caractère quelconque" et "un ensemble quelconque de plusieurs caractères".
Le raffinement /any peut être utilisé en conjonction avec find (avec ou sans le raffinement /match)
Exemples:
str: "abcdefg"
print find/any str "c*f"
cdefg
print find/any str "??d"
bcdefg
email-list: [
mack@REBOL.dom
judy@somesite.dom
jack@REBOL.dom
biff@REBOL.dom
jenn@somesite.dom
]
foreach email email-list [
if find/any email *@REBOL.dom [print email]
]
mack@REBOL.dom
jack@REBOL.dom
biff@REBOL.dom
L'exemple suivant utilise le raffinement /match
pour tenter de trouver une correspondance à un modéle sur l'ensemble de la série:
file-list: [
%REBOL.exe
%notes.html
%setup.html
%feedback.r
%nntp.r
%rebdoc.r
%REBOL.r
%user.r
]
foreach file file-list [
if find/match/any file %reb*.r [print file]
]
rebdoc.r
REBOL.r
none
Si l'un ou l'autre des caractères jokers standards (*) et (?) font partie de ce
qui devrait être à trouver, des caractères de substitution différents peuvent être spécifiés
avec le raffinement /with.
8.9 Fonction select
Une variante commode de la fonction find est la fonction select,
qui retourne la valeur qui suit celle trouvée.
La fonction select est souvent utilisée pour consulter une valeur dans des
blocs de données. La fonction select prend les mêmes types d'arguments que la fonction find :
la série où chercher et la valeur à trouver.
Cependant, contrairement à find, qui renvoie une position dans la série, la fonction select
retourne la valeur qui suit la correspondance.
colors: [red green blue yellow orange]
print select colors 'green
blue
La fonction select peut être utilisée pour accéder au contenu d'une petite
base de données :
email-book: [
"George" harrison@guru.org
"Paul" lefty@bass.edu
"Ringo" richard@starkey.dom
"Robert" service@yukon.dom
]
Le code suivant détermine une adresse email spécifique :
print select email-book "Paul"
lefty@bass.edu
Il est possible d'employer la fonction select pour extraire un bloc d'expressions, qui peut être évalué ensuite.
Par exemple, avec les données suivantes :
cases: [
10 [print "ten"]
20 [print "twenty"]
30 [print "thirty"]
]
un bloc peut ainsi être évalué grâce à select :
do select cases 10
ten
do select cases 30
thirty
8.10 Recherche et remplacement
Pour remplacer des valeurs au sein d'une série, vous pouvez utiliser la fonction replace.
Cette fonction recherche une valeur particulière dans une série, puis la remplace par une autre.
La fonction replace prend trois arguments : la série où chercher, la valeur à remplacer, et la nouvelle valeur.
str: "hello world hello"
probe replace str "hello" "aloha"
"aloha world hello"
data: [1 2 8 4 5]
probe replace data 8 3
[1 2 3 4 5]
probe replace data 4 `four
[1 2 3 four 5]
probe replace data integer! 0
[0 2 3 four 5]
Utiliser le raffinement /all pour remplacer toutes les occurences trouvées depuis la position courante
jusqu'à la fin de la série.
probe replace/all data integer! 0
[0 0 0 four 0]
code: [print "hello" print "world"]
replace/all code 'print 'probe
probe code
[probe "hello" probe "world"]
do code
helloworld
str: "hello world hello"
probe replace/all str "hello" "aloha"
"aloha world aloha"
9. Trier une série
La fonction sort offre une méthode simple et rapide de trier des séries.
Elle est plus pratique pour des blocs de données, mais peut aussi être
utilisée sur des chaînes de caractères.
9.1 Tri simple
Les exemples de tris les plus simples sont :
names: [Eve Luke Zaphod Adam Matt Betty]
probe sort names
[Adam Betty Eve Luke Matt Zaphod]
print sort [321.3 78 321 42 321.8 12 98]
12 42 78 98 321 321.3 321.8
print sort "plosabelm"
abellmops
Remarquez que sort a un effet destructeur sur la série fournie en argument.
Elle modifie l'ordre des données d'origine. Pour éviter cela, utilisez copy, comme dans
l'exemple suivant :
probe sort copy names
Par défaut, le tri est insensible à la casse :
print sort ["Fred" "fred" "FRED"]
Fred fred FRED
print sort "G4C28f9I15Ed3bA076h"
0123456789AbCdEfGhI
Mais avec le raffinement /case, le tri devient sensible aux majuscules/minuscules :
print sort/case "gCcAHfiEGeBIdbFaDh"
ABCDEFGHIabcdefghi
print sort/case ["Fred" "fred" "FRED"]
FRED Fred fred
print sort/case "g4Dc2BI8fCF9i15eAd3bGaE07H6h"
0123456789ABCDEFGHIabcdefghi
Beaucoup d'autres types de données peuvent être triées :
print sort [1.3.3.4 1.2.3.5 2.2.3.4 1.2.3.4]
1.2.3.4 1.2.3.5 1.3.3.4 2.2.3.4
print sort [$4.23 $23.45 $62.03 $23.23 $4.22]
$4.22 $4.23 $23.23 $23.45 $62.03
print sort [11:11:43 4:12:53 4:14:53 11:11:42]
4:12:53 4:14:53 11:11:42 11:11:43
print sort [11-11-1999 10-11-9999 11-4-1999 11-11-1998]
11-Nov-1998 11-Apr-1999 11-Nov-1999 10-Nov-9999
print sort [john@doe.dom jane@doe.dom jack@jill.dom]
jack@jill.dom jane@doe.dom john@doe.dom
print sort [%user.r %REBOL.r %history.r %notes.html]
history.r notes.html REBOL.r user.r
9.2 Tri par groupe
Souvent, il est nécessaire de trier un ensemble de données comme des enregistrements comprenant plus d'une valeur.
Le raffinement /skip permet de trier des enregistrements ayant une longueur fixe.
Ce raffinement prend un argument supplémentaire : un nombre entier indiquant la longueur de chaque enregistrement.
Voici un exemple qui trie un bloc contenant des prénoms, noms, âges, et emails.
Le bloc est tri selon la première colonne, le prénom.
names: [
"Evie" "Jordan" 43 eve@jordan.dom
"Matt" "Harrison" 87 matt@harrison.dom
"Luke" "Skywader" 32 luke@skywader.dom
"Beth" "Landwalker" 104 beth@landwalker.dom
"Adam" "Beachcomber" 29 adam@bc.dom
]
sort/skip names 4
foreach [first-name last-name age email] names [
print [first-name last-name age email]
]
Adam Beachcomber 29 adam@bc.dom
Beth Landwalker 104 beth@landwalker.dom
Evie Jordan 43 eve@jordan.dom
Luke Skywader 32 luke@skywader.dom
Matt Harrison 87 matt@harrison.dom
9.3 Fonctions de comparaison
Le raffinement /compare permet de réaliser des comparaisons spécifiques sur les données
au cours du tri.
Ce raffinement nécessite un argument supplémentaire, qui est la
fonction de comparaison à utiliser pour trier les données.
Une fonction de comparaison est écrite comme une fonction normale, mais prend deux arguments.
Ces arguments sont les valeurs à comparer. Une fonction de comparaison renvoie true si la
première valeur doit être placée avant la seconde et false si elle doit être
mise après .
Une comparaison classique place des données dans l'ordre croissant :
ascend: func [a b] [a < b]
Si la première valeur est inférieure à la deuxième, alors true est retourné par la fonction, et
la première valeur est placée avant la deuxième valeur.
data: [100 101 -20 37 42 -4]
probe sort/compare data :ascend
[-20 -4 37 42 100 101]
Pareillement :
descend: func [a b] [a > b]
Si la première valeur est supérieure à la seconde , alors la valeur true est renvoyée et les données sont
triées avec les plus grandes valeurs d'abord. Le tri s'effectue dans l'ordre décroissant.
probe sort/compare data :descend
[101 100 42 37 -4 -20]
Noter que dans chacun des cas la fonction de comparaison est passée avec son nom précédé de deux points.
Le nom précédé de deux points force la fonction à être passée à sort sans être d'abord évaluée.
La fonction de comparaison peut aussi être fournie directement :
probe sort/compare data func [a b] [a > b]
[101 100 42 37 -4 -20]
10. Série en tant qu'ensemble de données
Quelques fonctions travaillent sur les séries en tant qu'ensemble de données.
Ces fonctions permettent de réaliser des opérations comme trouver l'intersection ou l'union de deux séries.
10.1 Unique
La fonction unique renvoie un ensemble de valeurs sans doublons.
Exemples:
data: [Bill Betty Bob Benny Bart Bob Bill Bob]
probe unique data
[Bill Betty Bob Benny Bart]
print unique "abracadabra"
abrcd
10.2 Intersect
La fonction intersect prend deux séries en arguments et retourne
une série contenant leurs valeurs communes .
Exemples:
probe intersect [Bill Bob Bart] [Bob Ted Fred]
[Bob]
lunch: [ham cheese bread carrot]
dinner: [ham salad carrot rice]
probe intersect lunch dinner
[ham carrot]
print intersect [1 3 2 4] [3 5 4 6]
3 4
string1: "CBAD" ; A B C D scrambled
string2: "EDCF" ; C D E F scrambled
print sort intersect string1 string2
CD
Intersect peut être utilisée entre "bitsets" :
all-chars: "ABCDEFGHI"
charset1: charset "ABCDEF"
charset2: charset "DEFGHI"
charset3: intersect charset1 charset2
print find charset3 "E"
true
print find charset3 "B"
false
Le raffinement /case permet d'extraire les valeurs communes aux deux séries, en tenant
compte de la casse :
probe intersect/case [Bill bill Bob bob] [Bart bill Bob]
[bill Bob]
10.3 Union
La fonction union prend deux séries en arguments et renvoie une série réunissant les
valeurs de chacune , mais sans doublons.
Exemples :
probe union [Bill Bob Bart] [Bob Ted Fred]
[Bill Bob Bart Ted Fred]
lunch: [ham cheese bread carrot]
dinner: [ham salad carrot rice]
probe union lunch dinner
[ham cheese bread carrot salad rice]
print union [1 3 2 4] [3 5 4 6]
1 3 2 4 5 6
string1: "CBDA" ; A B C D scrambled
string2: "EDCF" ; C D E F scrambled
print sort union string1 string2
ABCDEF
La fonction union peut aussi travailler avec des "bitsets" :
charset1: charset "ABCDEF"
charset2: charset "DEFGHI"
charset3: union charset1 charset2
print find charset3 "C"
true
print find charset3 "G"
true
Le raffinement /case donne à la fonction union une sensibilité
à la casse, les majuscules et minuscules seront distinguées :
probe union/case [Bill bill Bob bob] [bill Bob]
[Bill bill Bob bob]
10.4 Difference
La fonction difference prend deux séries en arguments et renvoie une série qui
contient toutes les valeurs qui ne sont pas communes aux deux.
Exemples:
probe difference [1 2 3 4] [1 2 3 5]
[4 5]
probe difference [Bill Bob Bart] [Bob Ted Fred]
[Bill Bart Ted Fred]
lunch: [ham cheese bread carrot]
dinner: [ham salad carrot rice]
probe difference lunch dinner
[cheese bread salad rice]
string1: "CBAD" ; A B C D scrambled
string2: "EDCF" ; C D E F scrambled
print sort difference string1 string2
ABEF
Là encore, le raffinement /case permet d'utiliser la fonction difference avec une sensibilité aux
majuscules/minuscules.
probe difference/case [Bill bill Bob bob] [Bart bart bill Bob]
[Bill bob Bart bart]
10.5 Exclude
NDT : ce paragraphe est le regroupement de deux parties du document original sur la fonction exclude.
Une variante de la fonction difference est la fonction exclude.
La fonction exclude prend deux séries en arguments et renvoie une série
qui va contenir toutes les valeurs de la première série, moins celles, communes aux deux, de la deuxième série.
Exemples :
probe exclude [1 2 3 4] [1 2 3 5]
[4]
(Notez que le résultat ci-dessus ne contient pas 5 comme c'était le cas avec la fonction difference
vue précedemment.)
probe exclude [Bill Bob Bart] [Bob Ted Fred]
[Bill Bart]
probe exclude "abcde" "ace"
"bd"
lunch: [ham cheese bread carrot]
dinner: [ham salad carrot rice]
probe exclude lunch dinner
[cheese bread]
string1: "CBAD" ; A B C D scrambled
string2: "EDCF" ; C D E F scrambled
print sort difference string1 string2
AB
Le raffinement /case permet une exclusion sensible à la casse :
probe exclude/case [Bill bill Bob bob] [Bart bart bill Bob]
[Bill bob]
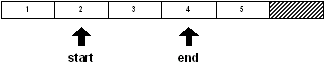
11. Multiples variables de série
Plusieurs variables de série peuvent référencer la même série.
Par exemple :
data: [1 2 3 4 5]
start: find data 3
end: find start 4
print first start
2
print first end
4
Les variables "start" et "end" font réference à la même série.
Elles pointent différentes positions, mais la série qu'elles référencent est la même.
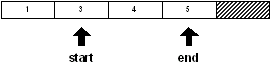
Si on utilise les fonctions insert ou remove sur une série, les valeurs dans la série sont décalées,
et les variables "start" et "end" peuvent ne plus se rapporter aux mêmes valeurs.
Par exemple, si une valeur est enlevée de la série à la position de "start" :
remove start
print first start
3
print first end
5
La série a été décalée vers la gauche et les variables se rapportent à présent à différentes valeurs
Notez que les positions d'index des variables n'ont pas changées,
mais ce sont les valeurs de la série qui ont changées.
La même situation peut se produire en utilisant la fonction insert.
Parfois cet effet secondaire fonctionnera à votre avantage.
Parfois non, et cela vous obligera à modifier votre code.
12. Raffinements de modification
Les fonctions change, insert, et remove peuvent prendre
des raffinements supplémentaires pour modifier leur comportement.
12.1 Part
Le raffinement /part accepte un nombre ou
une position de la série et l'utilise pour limiter l'effet de la fonction.
Par exemple, avec la série suivante :
str: "abcdef"
blk: [1 2 3 4 5 6]
vous pouvez changer une partie de "str" et "blk" en utilisant change/part :
change/part str [1 2 3 4] 3
probe str
1234def
change/part blk "abcd" 3
probe blk
["abcd" 4 5 6]
Vous pouvez insérer une partie d'une série à la fin de "str" et de "blk" en utilisant insert/part.
insert/part tail str "-ghijkl" 4
probe str
1234def-ghi
insert/part tail blk ["--" 7 8 9 10 11 12] 4
probe blk
["abcd" 4 5 6 "--" 7 8 9]
Pour ôter un morceau des séries "str" et "blk", utiliser remove/part.
Noter comment find est utilisé pour obtenir la position de la série :
remove/part (find str "d") (find str "-")
probe str
1234-ghi
remove/part (find blk 4) (find blk "--")
probe blk
["abcd" "--" 7 8 9]
12.2 Only
Le raffinement /only modifie ou insére un bloc tel quel plutôt que ses valeurs propres.
Exemples:
blk: [1 2 3 4 5 6]
Vous pouvez remplacer la valeur 2 dans le bloc "blk" avec le bloc
[a b c] et insérer le bloc [$1 $2 $3] à la position du 5.
change/only (find blk 2) [a b c]
probe blk
[1 [a b c] 3 4 5 6]
insert/only (find blk 5) [$1 $2 $3]
probe blk
[1 [a b c] 3 4 [$1.00 $2.00 $3.00] 5 6]
12.3 Dup
Le raffinement /dup modifie ou insére une valeur un certain nombre de fois
Exemples:
str: "abcdefghi"
blk: [1 2 3 4 5 6]
Vous pouvez changer les quatre premières valeurs dans la série "str" ou "blk" pour une astérisque (*) avec :
change/dup str "*" 4
probe str
****efghi
change/dup blk "*" 4
probe blk
["*" "*" "*" "*" 5 6]
Pour insérer un tiret (-) quatre fois avant la dernière valeur dans la chaîne ou le bloc :
insert/dup (back tail str) #"-" 4
probe str
****efgh----i
insert/dup (back tail blk) #"-" 4
probe blk
["*" "*" "*" "*" 5 #"-" #"-" #"-" #"-" 6]
Updated 7-Apr-2005 - Copyright REBOL Technologies - Formatted with MakeDoc2 - Translation by Philippe Le Goff
|